Hello, I'm Arpit Singh Gautam
I am a Data Scientist in the CSG CTO Lab at Dell Technologies, working on efficient LLM inference and the reliability of large models. My research identity is efficiency × reliability for foundation models: making large models cheaper to run and more trustworthy.
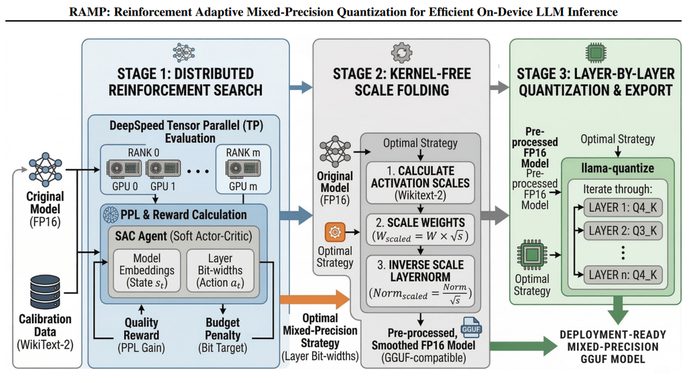
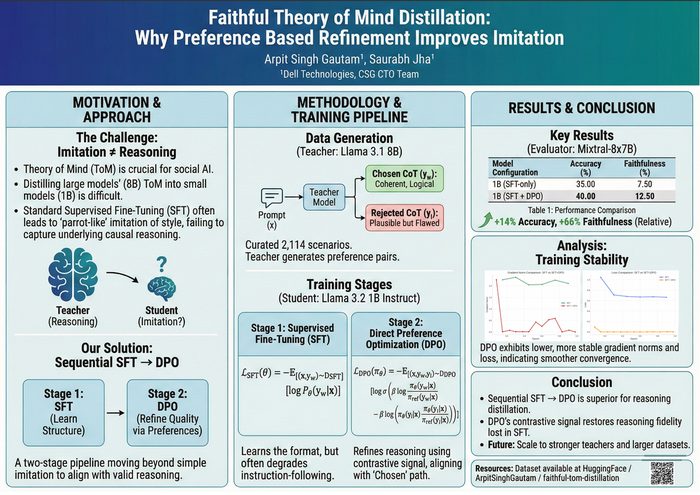
My deepest current line is the reliability of quantized models - what post-training quantization does to calibration, factual recall, and security, and how to preserve each cheaply. My work appears at EACL 2026 (FEVER) and AAAI 2026 (ToM), with preprints on RL-based quantization (RAMP) and disaggregated LLM serving (StreamServe).
Research interests: LLM systems & efficient inference - quantization, KV-cache optimization, serving · Trustworthy / honest LLMs - hallucination, calibration, safety · Reinforcement learning & reasoning for foundation models · Interpretability / mechanistic ML

Recent Updates
Papers · Projects · Talks · Blog posts - all in one place.